A data warehouse was defined by Bill Inmon as "a subject-oriented, integrated, nonvolatile, and time-variant collection of data in support of management's decisions" over 30 years ago. However, the initial data warehouses unable to store massive heterogeneous data, hence the creation of data lakes. In modern times, data lakehouse emerges as a new paradigm. It is an open data management architecture featured by strong data analytics and governance capabilities, high flexibility, and open storage.
If I could only use one word to describe the next-gen data lakehouse, it would be unification:
- Unified data storage to avoid the trouble and risks brought by redundant storage and cross-system ETL.
- Unified governance of both data and metadata with support for ACID, Schema Evolution, and Snapshot.
- Unified data application that supports data access via a single interface for multiple engines and workloads.
Let's look into the architecture of a data lakehouse. We will find that it is not only supported by table formats such as Apache Iceberg, Apache Hudi, and Delta Lake, but more importantly, it is powered by a high-performance query engine to extract value from data.
Users are looking for a query engine that allows quick and smooth access to the most popular data sources. What they don't want is for their data to be locked in a certain database and rendered unavailable for other engines or to spend extra time and computing costs on data transfer and format conversion.
To turn these visions into reality, a data query engine needs to figure out the following questions:
- How to access more data sources and acquire metadata more easily?
- How to improve query performance on data coming from various sources?
- How to enable more flexible resource scheduling and workload management?
Apache Doris provides a possible answer to these questions. It is a real-time OLAP database that aspires to build itself into a unified data analysis gateway. This means it needs to be easily connected to various RDBMS, data warehouses, and data lake engines (such as Hive, Iceberg, Hudi, Delta Lake, and Flink Table Store) and allow for quick data writing from and queries on these heterogeneous data sources. The rest of this article is an in-depth explanation of Apache Doris' techniques in the above three aspects: metadata acquisition, query performance optimization, and resource scheduling.
Metadata Acquisition and Data Access
Apache Doris 1.2.2 supports a wide variety of data lake formats and data access from various external data sources. Besides, via the Table Value Function, users can analyze files in object storage or HDFS directly.

To support multiple data sources, Apache Doris puts efforts into metadata acquisition and data access.
Metadata Acquisition
Metadata consists of information about the databases, tables, partitions, indexes, and files from the data source. Thus, metadata of various data sources come in different formats and patterns, adding to the difficulty of metadata connection. An ideal metadata acquisition service should include the following:
- A metadata structure that can accommodate heterogeneous metadata.
- An extensible metadata connection framework that enables quick and low-cost data connection.
- Reliable and efficient metadata access that supports real-time metadata capture.
- Custom authentication services to interface with external privilege management systems and thus reduce migration costs.
Metadata Structure
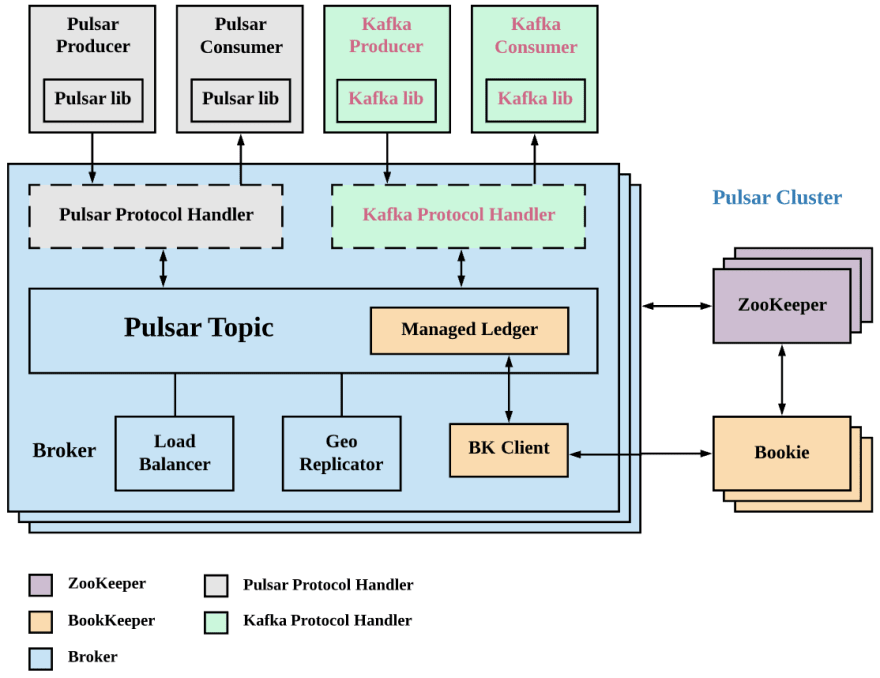
Older versions of Doris support a two-tiered metadata structure: database and table. As a result, users need to create mappings for external databases and tables one by one, which is heavy work. Thus, Apache Doris 1.2.0 introduced the Multi-Catalog functionality. With this, you can map to external data at the catalog level, which means:
- You can map to the whole external data source and ingest all metadata from it.
- You can manage the properties of the specified data source at the catalog level, such as connection, privileges, and data ingestion details, and easily handle multiple data sources.
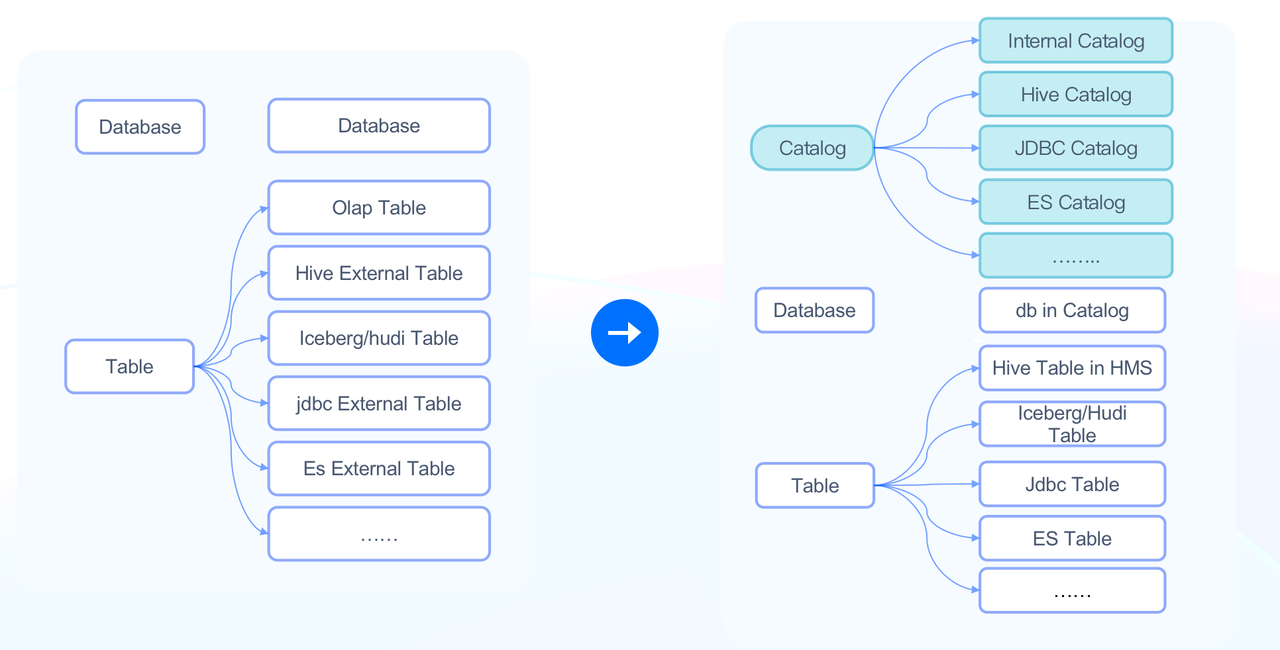
Data in Doris falls into two types of catalogs:
- Internal Catalog: Existing Doris databases and tables all belong to the Internal Catalog.
- External Catalog: This is used to interface with external data sources. For example, HMS External Catalog can be connected to a cluster managed by Hive Metastore, and Iceberg External Catalog can be connected to an Iceberg cluster.
You can use the SWITCH statement to switch catalogs. You can also conduct federated queries using fully qualified names. For example:
SELECT * FROM hive.db1.tbl1 a JOIN iceberg.db2.tbl2 b
ON a.k1 = b.k1;
See more details here.
Extensible Metadata Connection Framework
The introduction of the catalog level also enables users to add new data sources simply by using the CREATE CATALOG statement:
CREATE CATALOG hive PROPERTIES (
'type'='hms',
'hive.metastore.uris' = 'thrift://172.21.0.1:7004',
);
In data lake scenarios, Apache Doris currently supports the following metadata services:
- Hive Metastore-compatible metadata services
- Alibaba Cloud Data Lake Formation
- AWS Glue
This also paves the way for developers who want to connect to more data sources via External Catalog. All they need is to implement the access interface.
Efficient Metadata Access
Access to external data sources is often hindered by network conditions and data resources. This requires extra efforts of a data query engine to guarantee reliability, stability, and real-timeliness in metadata access.
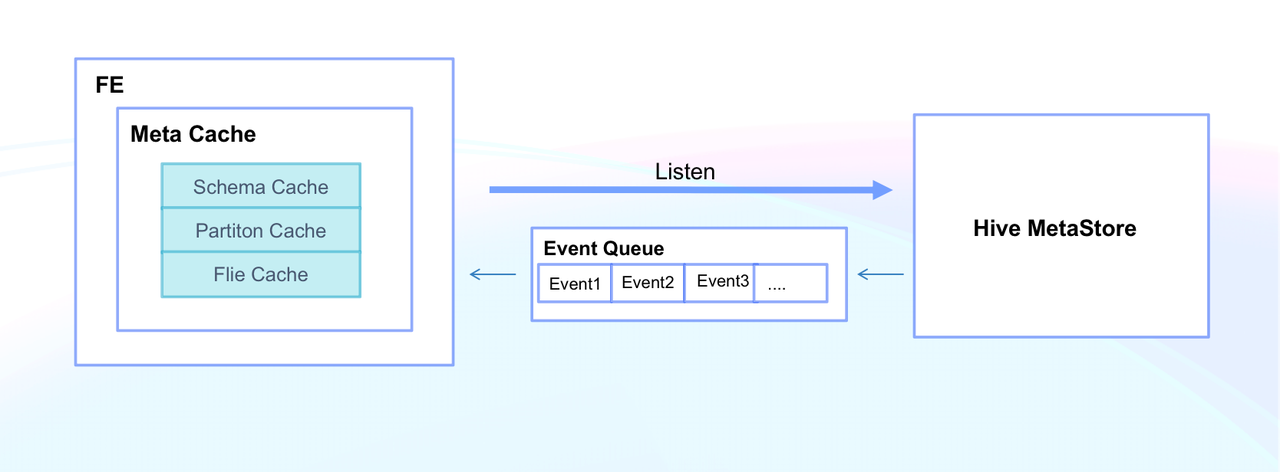
Doris enables high efficiency in metadata access by Meta Cache, which includes Schema Cache, Partition Cache, and File Cache. This means that Doris can respond to metadata queries on thousands of tables in milliseconds. In addition, Doris supports manual refresh of metadata at the Catalog/Database/Table level. Meanwhile, it enables auto synchronization of metadata in Hive Metastore by monitoring Hive Metastore Event, so any changes can be updated within seconds.
Custom Authorization
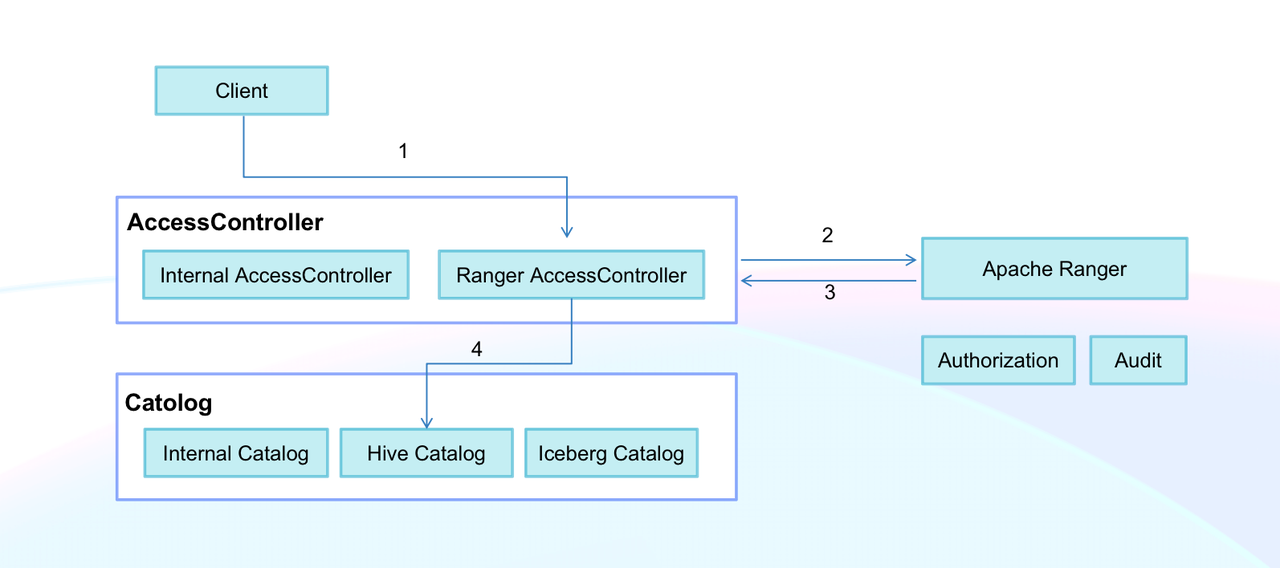
External data sources usually come with their own privilege management services. Many companies use one single tool (such as Apache Ranger) to provide authorization for their multiple data systems. Doris supports a custom authorization plugin, which can be connected to the user's own privilege management system via the Doris Access Controller interface. As a user, you only need to specify the authorization plugin for a newly created catalog, and then you can readily perform authorization, audit, and data encryption on external data in Doris.
Data Access
Doris supports data access to external storage systems, including HDFS and S3-compatible object storage:

Query Performance Optimization
After clearing the way for external data access, the next step for a query engine would be to accelerate data queries. In the case of Apache Doris, efforts are made in data reading, execution engine, and optimizer.
Data Reading
Reading data on remote storage systems is often bottlenecked by access latency, concurrency, and I/O bandwidth, so reducing reading frequency will be a better choice.
Native File Format Reader
Improving data reading efficiency entails optimizing the reading of Parquet files and ORC files, which are the most commonly seen data files. Doris has refactored its File Reader, which is fine-tuned for each data format. Take the Native Parquet Reader as an example:
- Reduce format conversion: It can directly convert files to the Doris storage format or to a format of higher performance using dictionary encoding.
- Smart indexing of finer granularity: It supports Page Index for Parquet files, so it can utilize Page-level smart indexing to filter Pages.
- Predicate pushdown and late materialization: It first reads columns with filters first and then reads the other columns of the filtered rows. This remarkably reduces file read volume since it avoids reading irrelevant data.
- Lower read frequency: Building on the high throughput and low concurrency of remote storage, it combines multiple data reads into one in order to improve overall data reading efficiency.
File Cache
Doris caches files from remote storage in local high-performance disks as a way to reduce overhead and increase performance in data reading. In addition, it has developed two new features that make queries on remote files as quick as those on local files:
- Block cache: Doris supports the block cache of remote files and can automatically adjust the block size from 4KB to 4MB based on the read request. The block cache method reduces read/write amplification and read latency in cold caches.
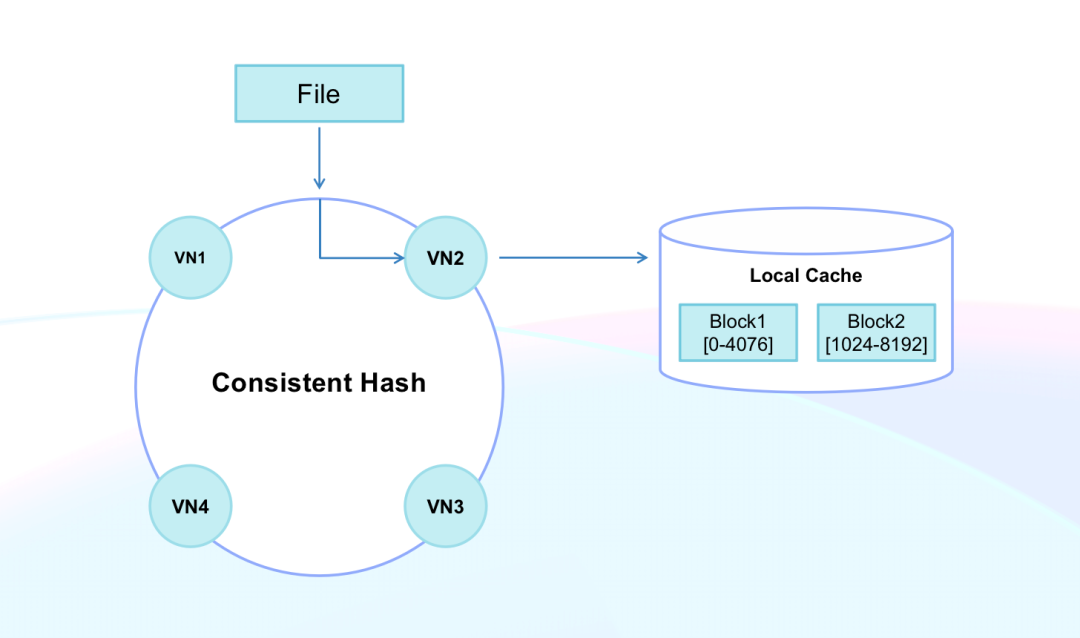
- Consistent hashing for caching: Doris applies consistent hashing to manage cache locations and schedule data scanning. By doing so, it prevents cache failures brought about by the online and offlining of nodes. It can also increase cache hit rate and query service stability.
Execution Engine
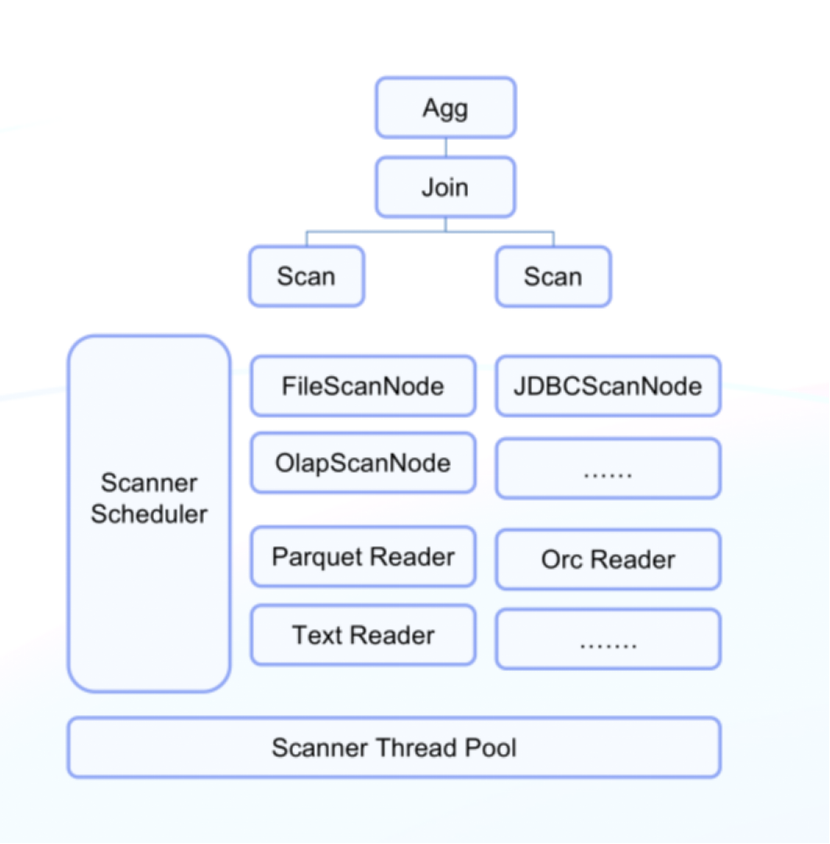
Developers surely don't want to rebuild all the general features for every new data source. Instead, they hope to reuse the vectorized execution engine and all operators in Doris in the data lakehouse scenario. Thus, Doris has refactored the scan nodes:
- Layer the logic: All data queries in Doris, including those on internal tables, use the same operators, such as Join, Sort, and Agg. The only difference between queries on internal and external data lies in data access. In Doris, anything above the scan nodes follows the same query logic, while below the scan nodes, the implementation classes will take care of access to different data sources.
- Use a general framework for scan operators: Even for the scan nodes, different data sources have a lot in common, such as task splitting logic, scheduling of sub-tasks and I/O, predicate pushdown, and Runtime Filter. Therefore, Doris uses interfaces to handle them. Then, it implements a unified scheduling logic for all sub-tasks. The scheduler is in charge of all scanning tasks in the node. With global information of the node in hand, the schedular is able to do fine-grained management. Such a general framework makes it easy to connect a new data source to Doris, which will only take a week of work for one developer.
Query Optimizer
Doris supports a range of statistical information from various data sources, including Hive Metastore, Iceberg Metafile, and Hudi MetaTable. It has also refined its cost model inference based on the characteristics of different data sources to enhance its query planning capability.
Performance
We tested Doris and Presto/Trino on HDFS in flat table scenarios (ClickBench) and multi-table scenarios (TPC-H). Here are the results:

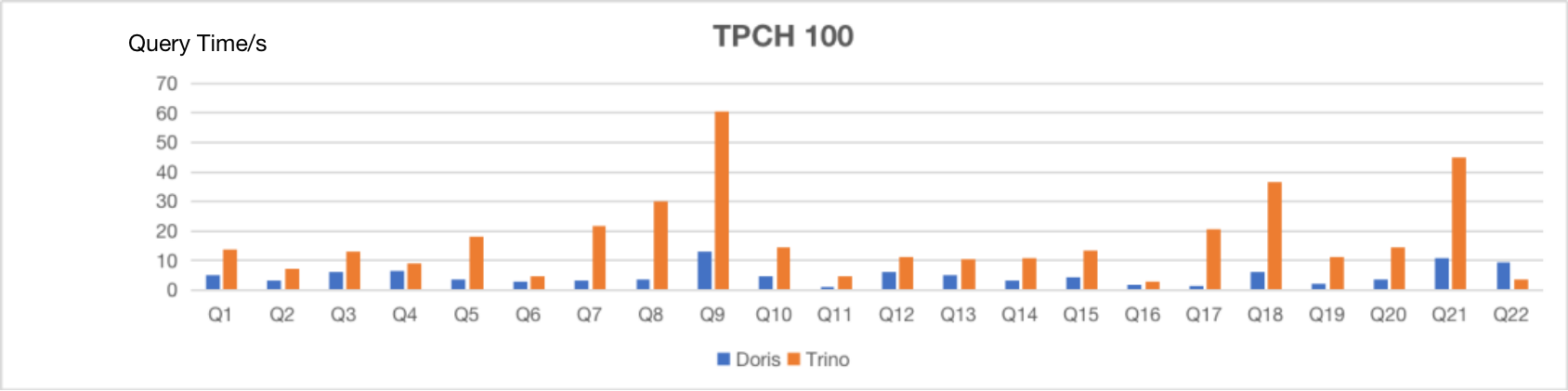
As is shown, with the same computing resources and on the same dataset, Apache Doris takes much less time to respond to SQL queries in both scenarios, delivering a 3~10 times higher performance than Presto/Trino.
Workload Management and Elastic Computing
Querying external data sources requires no internal storage of Doris. This makes elastic stateless computing nodes possible. Apache Doris 2.0 is going to implement Elastic Compute Node, which is dedicated to supporting query workloads of external data sources.
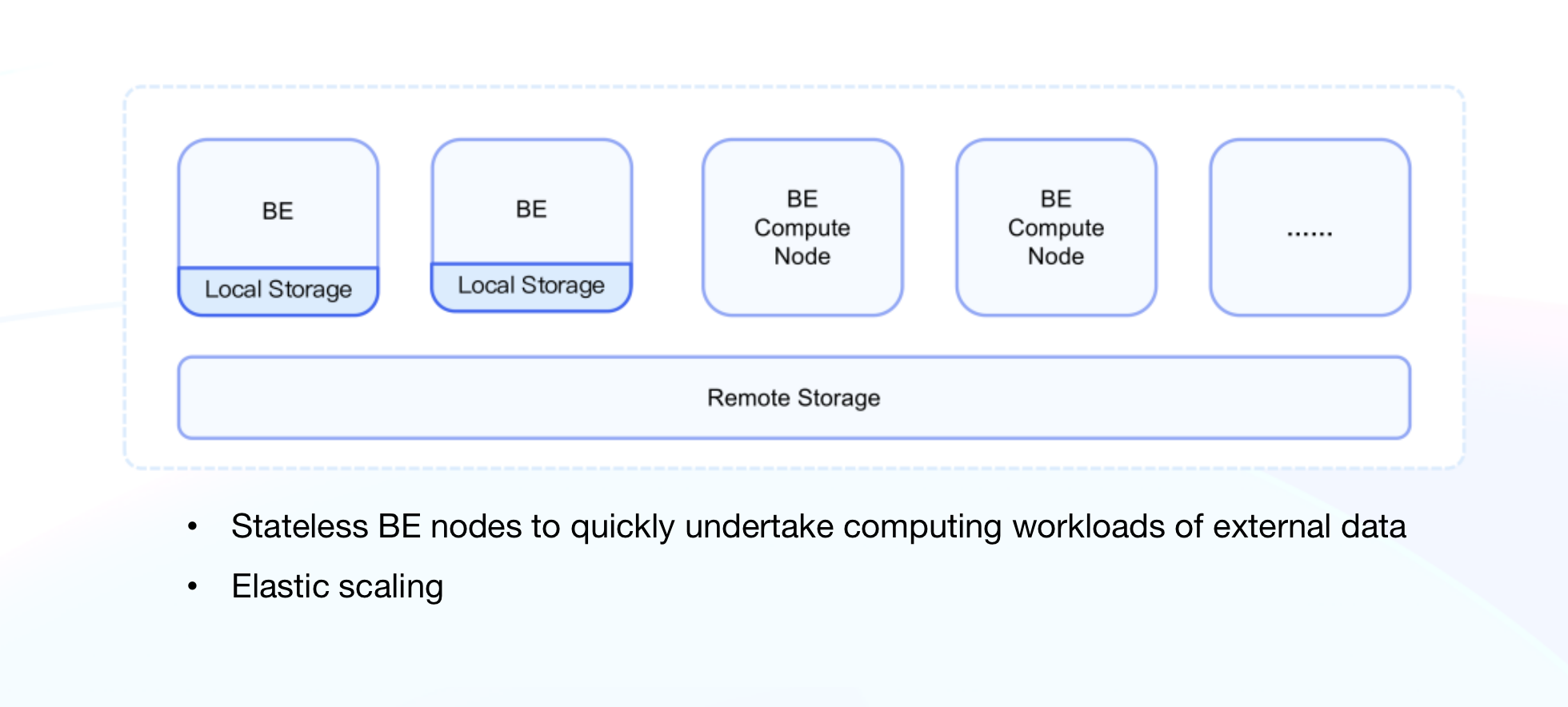
Stateless computing nodes are open for quick scaling so users can easily cope with query workloads during peaks and valleys and strike a balance between performance and cost. In addition, Doris has optimized itself for Kubernetes cluster management and node scheduling. Now Master nodes can automatically manage the onlining and offlining of Elastic Compute Nodes, so users can govern their cluster workloads in cloud-native and hybrid cloud scenarios without difficulty.
Use Case
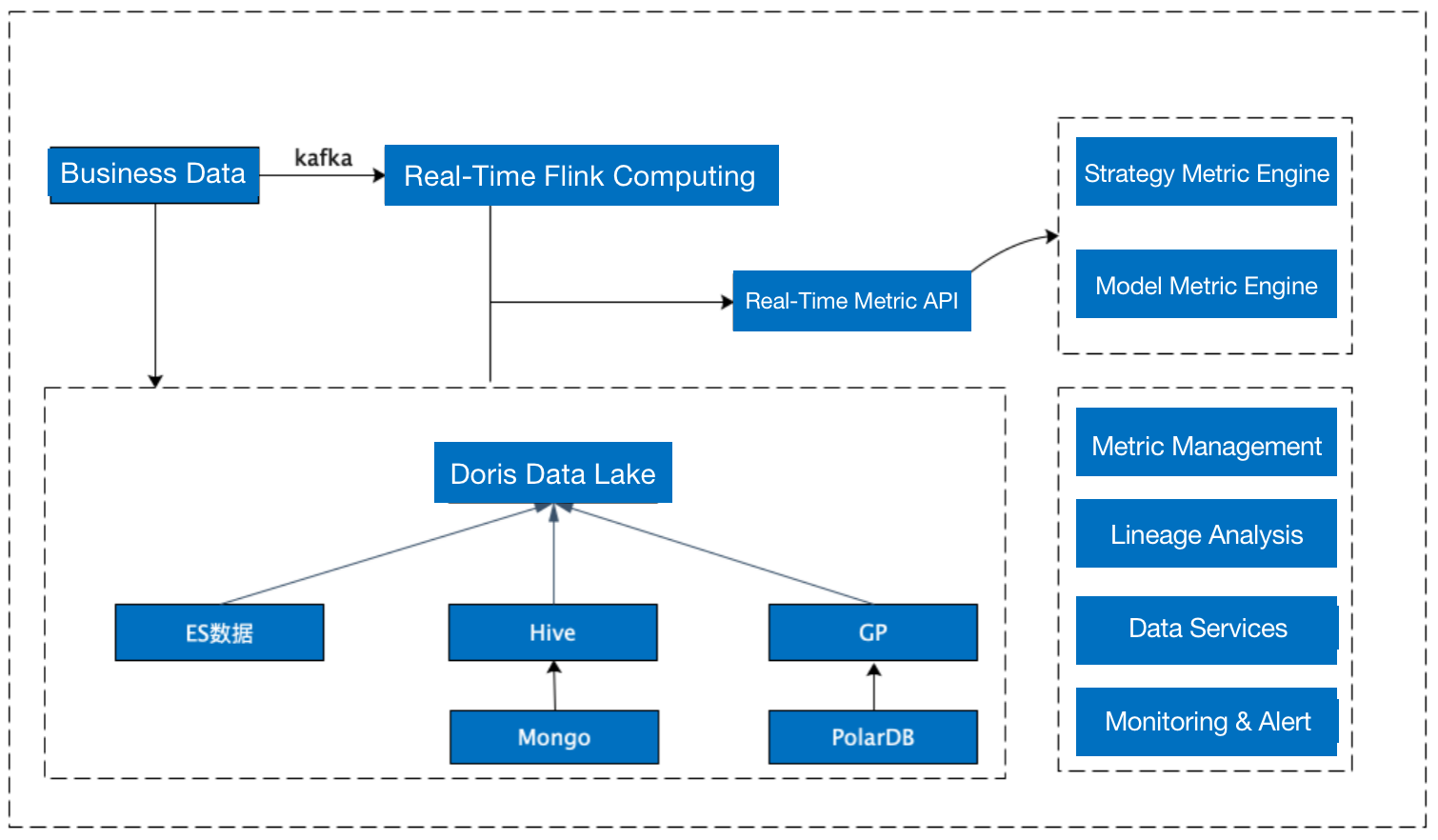
Apache Doris has been adopted by a financial institution for risk management. The user's high demands for data timeliness makes their data mart built on Greenplum and CDH, which could only process data from one day ago, no longer a great fit. In 2022, they incorporated Apache Doris in their data production and application pipeline, which allowed them to perform federated queries across Elasticsearch, Greenplum, and Hive. A few highlights from the user's feedback include:
- Doris allows them to create one Hive Catalog that maps to tens of thousands of external Hive tables and conducts fast queries on them.
- Doris makes it possible to perform real-time federated queries using Elasticsearch Catalog and achieve a response time of mere milliseconds.
- Doris enables the decoupling of daily batch processing and statistical analysis, bringing less resource consumption and higher system stability.
Future Plans
Apache Doris is going to support a wider range of data sources, improve its data reading and write-back functionality, and optimizes its resource isolation and scheduling.
More Data Sources
We are working closely with various open source communities to expand and improve Doris' features in data lake analytics. We plan to provide:
- Support for Incremental Query of Hudi Merge-on-Read tables;
- Lower query latency utilizing the indexing of Iceberg/Hudi in combination with the query optimizer;
- Support for more data lake formats such as Delta Lake and Flink Table Store.
Data Integration
Data reading:
Apache Doris is going to:
- Support CDC and Incremental Materialized Views for data lakes in order to provide users with near real-time data views;
- Support a Git-Like data access mode and enable easier and safer data management via the multi-version and Branch mechanisms.
Data Write-Back:
We are going to enhance Apache Doris' data analysis gateway. In the future, users will be able to use Doris as a unified data management portal that is in charge of the write-back of processed data, export of data, and the generation of a unified data view.
Resource Isolation & Scheduling
Apache Doris is undertaking a wider variety of workloads as it is interfacing with more and more data sources. For example, it needs to provide low-latency online services while batch processing T-1 data in Hive. To make it work, resource isolation within the same cluster is critical, which is where efforts will be made.
Meanwhile, we will continue optimizing the scheduling logic of elastic computing nodes in various scenarios and develop intra-node resource isolation at a finer granularity, such as CPU, I/O, and memory.
Join us
Contact dev@apache.doris.org to join the Lakehouse SIG(Special Interest Group) in the Apache Doris community and talk to developers from all walks of life.